
Kubernetes 日志采集 EFK
文章目录
!版权声明:本博客内容均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。
系统环境:
- Kubernetes 版本:1.14.0
- Fluentd 版本:1.4.2
- ElasticSearch 版本:6.7.0
- Kibana 版本:6.7.0
资源地址:
一、简单介绍
1、日志采集的必要性
Kubernetes 集群中会编排非常多的服务,各个服务不可能保证服务一定能稳定的运行,于是每个服务都会打印出各自的日志信息方便调试。由于服务的众多,每个服务挨个查看日志显然是一件非常复杂的事情,故而日志的统一收集、整理显得尤为重要。这里用流行方案 EFK 进行日志收集整理工作。
基于云原生十二原则规范,一般要求所有日志信息最好都打印输出到控制台,且打印出的日志都会以 *-json 的命名方式保存在 /var/lib/docker/containers/ 目录下,所以只要指定 Fluentd 收集地址为该目录即可方便进行日志收集工作。
2、Fluentd 简介
Fluentd是一个用于统一日志层的开源数据收集器。使用起来简单而灵活,且能统一记录层,经过全球多家公司实际考验其能力。
3、ElasticSearch 简介
Elasticsearch 是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便,轻松扩展服务节点,更能用于日志收集快速检索等等一些列功能。
4、Kibana 简介
Kibana是一个为Elasticsearch平台分析和可视化的开源平台,使用Kibana能够搜索、展示存储在Elasticsearch中的索引数据。使用它可以很方便用图表、表格、地图展示和分析数据。
二、安装 ElasticSearch、Kibana
请查看 “安装 ElasticSearch & Kibana”
三、日志采集过程
1、具体过程描述
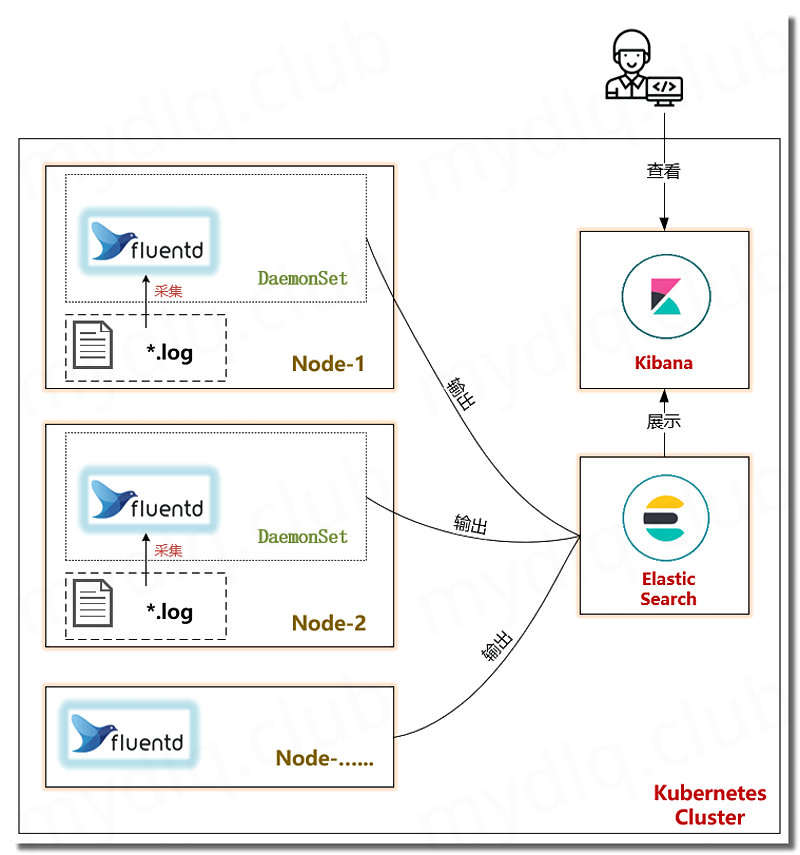
采集过程简单说就是利用 Fluentd 采集 Kubernetes 节点服务器的 "/var/log" 和 "/var/lib/docker/container" 两个目录下的日志信息,然后汇总到 ElasticSearch 集群中,再经过 Kibana 展示的一个过程。
具体日志收集过程如下所述:
- (1)、创建 Fluentd 并且将 Kubernetes 节点服务器 log 目录挂载进容器;
- (2)、Fluentd 启动采集 log 目录下的 containers 里面的日志文件;
- (3)、Fluentd 将收集的日志转换成 JSON 格式;
- (4)、Fluentd 利用 Exception Plugin 检测日志是否为容器抛出的异常日志,是就将异常栈的多行日志合并;
- (5)、Fluentd 将换行多行日志 JSON 合并;
- (6)、Fluentd 使用 Kubernetes Metadata Plugin 检测出 Kubernetes 的 Metadata 数据进行过滤,如 Namespace、Pod Name等;
- (7)、Fluentd 使用 ElasticSearch 插件将整理完的 JSON 日志输出到 ElasticSearch 中;
- (8)、ElasticSearch 建立对应索引,持久化日志信息。
- (9)、Kibana 检索 ElasticSearch 中 Kubernetes 日志相关信息进行展示。
2、简单日志收集过程图
四、准备 Fluentd 配置文件
详情请访问 Kubernetes Fluentd Github地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsearch
1、下载配置文件
下载 Kubernetes ConfigMap 的配置 yaml 文件,里面包含了 Fluentd 采集 Kubernetes 集群日志的相关配置,需要提前将其下载修改一些配置让其更适合我们 Kubernetes 集群日志采集。
1$ https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/fluentd-elasticsearch/fluentd-es-configmap.yaml
2、配置文件分析
下载完后查看配置文件,这里将描述个别重要的配置段。
1kind: ConfigMap
2apiVersion: v1
3metadata:
4 name: fluentd-es-config-v0.2.0
5 namespace: kube-system
6 labels:
7 addonmanager.kubernetes.io/mode: Reconcile
8data:
9 ###### 系统配置,默认即可 #######
10 system.conf: |-
11 <system>
12 root_dir /tmp/fluentd-buffers/
13 </system>
14
15 ###### 容器日志—收集配置 #######
16 containers.input.conf: |-
17 # ------采集 Kubernetes 容器日志-------
18 <source>
19 @id fluentd-containers.log
20 @type tail #---Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
21 path /var/log/containers/*.log #---挂载的服务器Docker容器日志地址
22 pos_file /var/log/es-containers.log.pos
23 tag raw.kubernetes.* #---设置日志标签
24 read_from_head true
25 <parse> #---多行格式化成JSON
26 @type multi_format #---使用multi-format-parser解析器插件
27 <pattern>
28 format json #---JSON解析器
29 time_key time #---指定事件时间的时间字段
30 time_format %Y-%m-%dT%H:%M:%S.%NZ #---时间格式
31 </pattern>
32 <pattern>
33 format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
34 time_format %Y-%m-%dT%H:%M:%S.%N%:z
35 </pattern>
36 </parse>
37 </source>
38
39 # -----检测Exception异常日志连接到一条日志中------
40 # 关于插件请查看地址:https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions
41 <match raw.kubernetes.**> #---匹配tag为raw.kubernetes.**日志信息
42 @id raw.kubernetes
43 @type detect_exceptions #---使用detect-exceptions插件处理异常栈信息,放置异常只要一行而不完整
44 remove_tag_prefix raw #---移出raw前缀
45 message log #---JSON记录中包含应扫描异常的单行日志消息的字段的名称。
46 # 如果将其设置为'',则插件将按此顺序尝试'message'和'log'。
47 # 此参数仅适用于结构化(JSON)日志流。默认值:''。
48 stream stream #---JSON记录中包含“真实”日志流中逻辑日志流名称的字段的名称。
49 # 针对每个逻辑日志流单独处理异常检测,即,即使逻辑日志流 的
50 # 消息在“真实”日志流中交织,也将检测到异常。因此,仅组合相
51 # 同逻辑流中的记录。如果设置为'',则忽略此参数。此参数仅适用于
52 # 结构化(JSON)日志流。默认值:''。
53 multiline_flush_interval 5 #---以秒为单位的间隔,在此之后将转发(可能尚未完成)缓冲的异常堆栈。
54 # 如果未设置,则不刷新不完整的异常堆栈。
55 max_bytes 500000
56 max_lines 1000
57 </match>
58
59 # -------日志拼接-------
60 <filter **>
61 @id filter_concat
62 @type concat #---Fluentd Filter插件,用于连接多个事件中分隔的多行日志。
63 key message
64 multiline_end_regexp /\n$/ #---以换行符“\n”拼接
65 separator ""
66 </filter>
67
68 # ------过滤Kubernetes metadata数据使用pod和namespace metadata丰富容器日志记录-------
69 # 关于插件请查看地址:https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter
70 <filter kubernetes.**>
71 @id filter_kubernetes_metadata
72 @type kubernetes_metadata
73 </filter>
74
75 # ------修复ElasticSearch中的JSON字段------
76 # 关于插件请查看地址:https://github.com/repeatedly/fluent-plugin-multi-format-parser
77 <filter kubernetes.**>
78 @id filter_parser
79 @type parser #---multi-format-parser多格式解析器插件
80 key_name log #---在要解析的记录中指定字段名称。
81 reserve_data true #---在解析结果中保留原始键值对。
82 remove_key_name_field true #---key_name解析成功后删除字段。
83 <parse>
84 @type multi_format
85 <pattern>
86 format json
87 </pattern>
88 <pattern>
89 format none
90 </pattern>
91 </parse>
92 </filter>
93
94 ###### Kubernetes集群节点机器上的日志收集 ######
95 system.input.conf: |-
96 # ------Kubernetes minion节点日志信息,可以去掉------
97 #<source>
98 # @id minion
99 # @type tail
100 # format /^(?<time>[^ ]* [^ ,]*)[^\[]*\[[^\]]*\]\[(?<severity>[^ \]]*) *\] (?<message>.*)$/
101 # time_format %Y-%m-%d %H:%M:%S
102 # path /var/log/salt/minion
103 # pos_file /var/log/salt.pos
104 # tag salt
105 #</source>
106
107 # ------启动脚本日志,可以去掉------
108 # <source>
109 # @id startupscript.log
110 # @type tail
111 # format syslog
112 # path /var/log/startupscript.log
113 # pos_file /var/log/es-startupscript.log.pos
114 # tag startupscript
115 # </source>
116
117 # ------Docker 程序日志,可以去掉------
118 # <source>
119 # @id docker.log
120 # @type tail
121 # format /^time="(?<time>[^)]*)" level=(?<severity>[^ ]*) msg="(?<message>[^"]*)"( err="(?<error>[^"]*)")?( statusCode=($<status_code>\d+))?/
122 # path /var/log/docker.log
123 # pos_file /var/log/es-docker.log.pos
124 # tag docker
125 # </source>
126
127 #------ETCD 日志,因为ETCD现在默认启动到容器中,采集容器日志顺便就采集了,可以去掉------
128 # <source>
129 # @id etcd.log
130 # @type tail
131 # # Not parsing this, because it doesn't have anything particularly useful to
132 # # parse out of it (like severities).
133 # format none
134 # path /var/log/etcd.log
135 # pos_file /var/log/es-etcd.log.pos
136 # tag etcd
137 # </source>
138
139 #------Kubelet 日志------
140 # <source>
141 # @id kubelet.log
142 # @type tail
143 # format multiline
144 # multiline_flush_interval 5s
145 # format_firstline /^\w\d{4}/
146 # format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
147 # time_format %m%d %H:%M:%S.%N
148 # path /var/log/kubelet.log
149 # pos_file /var/log/es-kubelet.log.pos
150 # tag kubelet
151 # </source>
152
153 #------Kube-proxy 日志------
154 # <source>
155 # @id kube-proxy.log
156 # @type tail
157 # format multiline
158 # multiline_flush_interval 5s
159 # format_firstline /^\w\d{4}/
160 # format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
161 # time_format %m%d %H:%M:%S.%N
162 # path /var/log/kube-proxy.log
163 # pos_file /var/log/es-kube-proxy.log.pos
164 # tag kube-proxy
165 # </source>
166
167 #------kube-apiserver日志------
168 # <source>
169 # @id kube-apiserver.log
170 # @type tail
171 # format multiline
172 # multiline_flush_interval 5s
173 # format_firstline /^\w\d{4}/
174 # format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
175 # time_format %m%d %H:%M:%S.%N
176 # path /var/log/kube-apiserver.log
177 # pos_file /var/log/es-kube-apiserver.log.pos
178 # tag kube-apiserver
179 # </source>
180
181 #------Kube-controller日志------
182 # <source>
183 # @id kube-controller-manager.log
184 # @type tail
185 # format multiline
186 # multiline_flush_interval 5s
187 # format_firstline /^\w\d{4}/
188 # format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
189 # time_format %m%d %H:%M:%S.%N
190 # path /var/log/kube-controller-manager.log
191 # pos_file /var/log/es-kube-controller-manager.log.pos
192 # tag kube-controller-manager
193 # </source>
194
195 #------Kube-scheduler日志------
196 # <source>
197 # @id kube-scheduler.log
198 # @type tail
199 # format multiline
200 # multiline_flush_interval 5s
201 # format_firstline /^\w\d{4}/
202 # format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
203 # time_format %m%d %H:%M:%S.%N
204 # path /var/log/kube-scheduler.log
205 # pos_file /var/log/es-kube-scheduler.log.pos
206 # tag kube-scheduler
207 # </source>
208
209 #------glbc日志------
210 # <source>
211 # @id glbc.log
212 # @type tail
213 # format multiline
214 # multiline_flush_interval 5s
215 # format_firstline /^\w\d{4}/
216 # format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
217 # time_format %m%d %H:%M:%S.%N
218 # path /var/log/glbc.log
219 # pos_file /var/log/es-glbc.log.pos
220 # tag glbc
221 # </source>
222
223 #------Kubernetes 伸缩日志------
224 # <source>
225 # @id cluster-autoscaler.log
226 # @type tail
227 # format multiline
228 # multiline_flush_interval 5s
229 # format_firstline /^\w\d{4}/
230 # format1 /^(?<severity>\w)(?<time>\d{4} [^\s]*)\s+(?<pid>\d+)\s+(?<source>[^ \]]+)\] (?<message>.*)/
231 # time_format %m%d %H:%M:%S.%N
232 # path /var/log/cluster-autoscaler.log
233 # pos_file /var/log/es-cluster-autoscaler.log.pos
234 # tag cluster-autoscaler
235 # </source>
236
237 # -------来自system-journal的日志------
238 <source>
239 @id journald-docker
240 @type systemd
241 matches [{ "_SYSTEMD_UNIT": "docker.service" }]
242 <storage>
243 @type local
244 persistent true
245 path /var/log/journald-docker.pos
246 </storage>
247 read_from_head true
248 tag docker
249 </source>
250
251 # -------Journald-container-runtime日志信息------
252 <source>
253 @id journald-container-runtime
254 @type systemd
255 matches [{ "_SYSTEMD_UNIT": "{{ fluentd_container_runtime_service }}.service" }]
256 <storage>
257 @type local
258 persistent true
259 path /var/log/journald-container-runtime.pos
260 </storage>
261 read_from_head true
262 tag container-runtime
263 </source>
264
265 # -------Journald-kubelet日志信息------
266 <source>
267 @id journald-kubelet
268 @type systemd
269 matches [{ "_SYSTEMD_UNIT": "kubelet.service" }]
270 <storage>
271 @type local
272 persistent true
273 path /var/log/journald-kubelet.pos
274 </storage>
275 read_from_head true
276 tag kubelet
277 </source>
278
279 # -------journald节点问题检测器------
280 #关于插件请查看地址:https://github.com/reevoo/fluent-plugin-systemd
281 #systemd输入插件,用于从systemd日志中读取日志
282 <source>
283 @id journald-node-problem-detector
284 @type systemd
285 matches [{ "_SYSTEMD_UNIT": "node-problem-detector.service" }]
286 <storage>
287 @type local
288 persistent true
289 path /var/log/journald-node-problem-detector.pos
290 </storage>
291 read_from_head true
292 tag node-problem-detector
293 </source>
294
295 # -------kernel日志------
296 <source>
297 @id kernel
298 @type systemd
299 matches [{ "_TRANSPORT": "kernel" }]
300 <storage>
301 @type local
302 persistent true
303 path /var/log/kernel.pos
304 </storage>
305 <entry>
306 fields_strip_underscores true
307 fields_lowercase true
308 </entry>
309 read_from_head true
310 tag kernel
311 </source>
312
313 ###### 监听配置,一般用于日志聚合用 ######
314 forward.input.conf: |-
315 #监听通过TCP发送的消息
316 <source>
317 @id forward
318 @type forward
319 </source>
320
321 ###### Prometheus metrics 数据收集 ######
322 monitoring.conf: |-
323 # input plugin that exports metrics
324 # 输出 metrics 数据的 input 插件
325 <source>
326 @id prometheus
327 @type prometheus
328 </source>
329 <source>
330 @id monitor_agent
331 @type monitor_agent
332 </source>
333 # 从 MonitorAgent 收集 metrics 数据的 input 插件
334 <source>
335 @id prometheus_monitor
336 @type prometheus_monitor
337 <labels>
338 host ${hostname}
339 </labels>
340 </source>
341 # ------为 output 插件收集指标的 input 插件------
342 <source>
343 @id prometheus_output_monitor
344 @type prometheus_output_monitor
345 <labels>
346 host ${hostname}
347 </labels>
348 </source>
349 # ------为in_tail 插件收集指标的input 插件------
350 <source>
351 @id prometheus_tail_monitor
352 @type prometheus_tail_monitor
353 <labels>
354 host ${hostname}
355 </labels>
356 </source>
357
358 ###### 输出配置,在此配置输出到ES的配置信息 ######
359 # ElasticSearch fluentd插件地址:https://docs.fluentd.org/v1.0/articles/out_elasticsearch
360 output.conf: |-
361 <match **>
362 @id elasticsearch
363 @type elasticsearch
364 @log_level info #---指定日志记录级别。可设置为fatal,error,warn,info,debug,和trace,默认日志级别为info。
365 type_name _doc
366 include_tag_key true #---将 tag 标签的 key 到日志中。
367 host elasticsearch-logging #---指定 ElasticSearch 服务器地址。
368 port 9200 #---指定 ElasticSearch 端口号。
369 #index_name fluentd.${tag}.%Y%m%d #---要将事件写入的索引名称(默认值:) fluentd。
370 logstash_format true #---使用传统的索引名称格式logstash-%Y.%m.%d,此选项取代该index_name选项。
371 #logstash_prefix logstash #---用于logstash_format指定为true时写入logstash前缀索引名称,默认值:logstash。
372 <buffer>
373 @type file #---Buffer 插件类型,可选file、memory
374 path /var/log/fluentd-buffers/kubernetes.system.buffer
375 flush_mode interval
376 retry_type exponential_backoff #---重试模式,可选为exponential_backoff、periodic。
377 # exponential_backoff 模式为等待秒数,将在每次失败时成倍增长
378 flush_thread_count 2
379 flush_interval 10s
380 retry_forever
381 retry_max_interval 30 #---丢弃缓冲数据之前的尝试的最大间隔。
382 chunk_limit_size 5M #---每个块的最大大小:事件将被写入块,直到块的大小变为此大小。
383 queue_limit_length 8 #---块队列的长度。
384 overflow_action block #---输出插件在缓冲区队列已满时的行为方式,有throw_exception、block、
385 # drop_oldest_chunk,block方式为阻止输入事件发送到缓冲区。
386 </buffer>
387 </match>
3、定制配置并调整参数
创建 fluentd-es-config.yaml 文件
1$ vi fluentd-es-config.yaml
添加如下内容:
1kind: ConfigMap
2apiVersion: v1
3metadata:
4 name: fluentd-es-config
5 namespace: logging
6 labels:
7 addonmanager.kubernetes.io/mode: Reconcile
8data:
9 #------系统配置参数-----
10 system.conf: |-
11 <system>
12 root_dir /tmp/fluentd-buffers/
13 </system>
14 #------Kubernetes 容器日志收集配置------
15 containers.input.conf: |-
16 <source>
17 @id fluentd-containers.log
18 @type tail
19 path /var/log/containers/*.log
20 pos_file /var/log/es-containers.log.pos
21 tag raw.kubernetes.*
22 read_from_head true
23 <parse>
24 @type multi_format
25 <pattern>
26 format json
27 time_key time
28 time_format %Y-%m-%dT%H:%M:%S.%NZ
29 </pattern>
30 <pattern>
31 format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/
32 time_format %Y-%m-%dT%H:%M:%S.%N%:z
33 </pattern>
34 </parse>
35 </source>
36 <match raw.kubernetes.**>
37 @id raw.kubernetes
38 @type detect_exceptions
39 remove_tag_prefix raw
40 message log
41 stream stream
42 multiline_flush_interval 5
43 max_bytes 500000
44 max_lines 1000
45 </match>
46 <filter **>
47 @id filter_concat
48 @type concat
49 key message
50 multiline_end_regexp /\n$/
51 separator ""
52 </filter>
53 <filter kubernetes.**>
54 @id filter_kubernetes_metadata
55 @type kubernetes_metadata
56 </filter>
57 <filter kubernetes.**>
58 @id filter_parser
59 @type parser
60 key_name log
61 reserve_data true
62 remove_key_name_field true
63 <parse>
64 @type multi_format
65 <pattern>
66 format json
67 </pattern>
68 <pattern>
69 format none
70 </pattern>
71 </parse>
72 </filter>
73 #------系统日志收集-------
74 system.input.conf: |-
75 <source>
76 @id journald-docker
77 @type systemd
78 matches [{ "_SYSTEMD_UNIT": "docker.service" }]
79 <storage>
80 @type local
81 persistent true
82 path /var/log/journald-docker.pos
83 </storage>
84 read_from_head true
85 tag docker
86 </source>
87 <source>
88 @id journald-container-runtime
89 @type systemd
90 matches [{ "_SYSTEMD_UNIT": "{{ fluentd_container_runtime_service }}.service" }]
91 <storage>
92 @type local
93 persistent true
94 path /var/log/journald-container-runtime.pos
95 </storage>
96 read_from_head true
97 tag container-runtime
98 </source>
99 <source>
100 @id journald-kubelet
101 @type systemd
102 matches [{ "_SYSTEMD_UNIT": "kubelet.service" }]
103 <storage>
104 @type local
105 persistent true
106 path /var/log/journald-kubelet.pos
107 </storage>
108 read_from_head true
109 tag kubelet
110 </source>
111 <source>
112 @id journald-node-problem-detector
113 @type systemd
114 matches [{ "_SYSTEMD_UNIT": "node-problem-detector.service" }]
115 <storage>
116 @type local
117 persistent true
118 path /var/log/journald-node-problem-detector.pos
119 </storage>
120 read_from_head true
121 tag node-problem-detector
122 </source>
123 <source>
124 @id kernel
125 @type systemd
126 matches [{ "_TRANSPORT": "kernel" }]
127 <storage>
128 @type local
129 persistent true
130 path /var/log/kernel.pos
131 </storage>
132 <entry>
133 fields_strip_underscores true
134 fields_lowercase true
135 </entry>
136 read_from_head true
137 tag kernel
138 </source>
139 #------输出到 ElasticSearch 配置------
140 output.conf: |-
141 <match **>
142 @id elasticsearch
143 @type elasticsearch
144 @log_level info
145 type_name _doc
146 include_tag_key true
147 host elasticsearch-client #改成自己的 ElasticSearch 地址
148 port 9200
149 logstash_format true
150 logstash_prefix kubernetes
151 logst
152 <buffer>
153 @type file
154 path /var/log/fluentd-buffers/kubernetes.system.buffer
155 flush_mode interval
156 retry_type exponential_backoff
157 flush_thread_count 5
158 flush_interval 8s
159 retry_forever
160 retry_max_interval 30
161 chunk_limit_size 5M
162 queue_limit_length 10
163 overflow_action block
164 compress gzip #开启gzip提高日志采集性能
165 </buffer>
166 </match>
五、安装 Fluentd
1、创建 Fluentd ConfigMap
1$ kubectl apply -f fluentd-es-config.yaml
2、创建 Flunetd ServiceAccount
创建 fluentd-rbac.yaml 文件
1$ vi fluentd-rbac.yaml
添加如下内容:
1apiVersion: v1
2kind: ServiceAccount
3metadata:
4 name: fluentd-es
5 namespace: logging
6 labels:
7 k8s-app: fluentd-es
8 addonmanager.kubernetes.io/mode: Reconcile
9---
10kind: ClusterRole
11apiVersion: rbac.authorization.k8s.io/v1
12metadata:
13 name: fluentd-es
14 labels:
15 k8s-app: fluentd-es
16 addonmanager.kubernetes.io/mode: Reconcile
17rules:
18- apiGroups:
19 - ""
20 resources:
21 - "namespaces"
22 - "pods"
23 verbs:
24 - "get"
25 - "watch"
26 - "list"
27---
28kind: ClusterRoleBinding
29apiVersion: rbac.authorization.k8s.io/v1
30metadata:
31 name: fluentd-es
32 labels:
33 k8s-app: fluentd-es
34 addonmanager.kubernetes.io/mode: Reconcile
35subjects:
36- kind: ServiceAccount
37 name: fluentd-es
38 namespace: logging
39 apiGroup: ""
40roleRef:
41 kind: ClusterRole
42 name: fluentd-es
43 apiGroup: ""
创建 Fluentd ServiceAccount
1$ kubectl apply -f fluentd-rbac.yaml
3、创建 Fluentd PriorityClass
当节点出现问题时,优先级低的 Pod 在资源不足时,容易首先被驱逐,因而对于重要的 daemonset 或者重要的应用组件,用户可以设置较高的优先级防止被抢占。这里创建一个优先级资源,方便后面应用到 fluentd。
创建 fluentd-rbac.yaml 文件
1$ vi fluentd-priorityclass.yaml
创建 fluenntd-priorityclass.yaml
1apiVersion: scheduling.k8s.io/v1beta1
2kind: PriorityClass
3metadata:
4 name: fluentd-priority
5value: 1000000
6globalDefault: false
7description: ""
创建 Fluentd PriorityClass
1$ kubectl apply -f fluentd-priorityclass.yaml
4、创建 Fluentd DaemonSet
创建 fluentd-rbac.yaml 文件
1$ vi fluentd.yaml
添加如下内容:
1apiVersion: apps/v1
2kind: DaemonSet
3metadata:
4 name: fluentd-es
5 namespace: logging
6 labels:
7 k8s-app: fluentd-es
8 version: v2.5.2
9 addonmanager.kubernetes.io/mode: Reconcile
10spec:
11 selector:
12 matchLabels:
13 k8s-app: fluentd-es
14 version: v2.5.2
15 template:
16 metadata:
17 labels:
18 k8s-app: fluentd-es
19 version: v2.5.2
20 #此注释确保如果节点被驱逐,fluentd不会被驱逐
21 #支持关键的基于pod注释的优先级方案。
22 annotations:
23 scheduler.alpha.kubernetes.io/critical-pod: ''
24 seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
25 spec:
26 priorityClassName: fluentd-priority #给 Fluentd 设置优先级资源
27 serviceAccountName: fluentd-es #给 Fluentd 分配权限账户
28 #设置容忍所有污点,这样可以收集所有节点日志如 Master 节点一般都被设污,不设置无法在其节点启动 fluentd。
29 tolerations:
30 - operator: "Exists"
31 containers:
32 - name: fluentd-es
33 image: mydlqclub/fluentd-elasticsearch:v2.5.2
34 env:
35 - name: FLUENTD_ARGS
36 value: --no-supervisor -q #不启用管理,-q 命令用平静时期于减少warn级别日志(-qq:减少error日志)
37 resources:
38 limits:
39 memory: 500Mi
40 requests:
41 cpu: 100m
42 memory: 200Mi
43 volumeMounts:
44 - name: varlog
45 mountPath: /var/log
46 - name: varlibdockercontainers
47 mountPath: /var/lib/docker/containers
48 readOnly: true
49 - name: config-volume
50 mountPath: /etc/fluent/config.d
51 terminationGracePeriodSeconds: 30 #Kubernetes 将会给应用发送SIGTERM信号,用来优雅地关闭应用
52 volumes:
53 - name: varlog #将 Kubernetes 节点服务器日志目录挂入
54 hostPath:
55 path: /var/log
56 - name: varlibdockercontainers #挂入 Docker 容器日志目录
57 hostPath:
58 path: /var/lib/docker/containers
59 - name: config-volume #挂入 Fluentd 的配置参数
60 configMap:
61 name: fluentd-es-config
- PS:由于谷歌镜像不可访问,所以上面镜像为本人自己发布到 docker 官方镜像仓库中的镜像。
- 镜像地址: mydlqclub/fluentd-elasticsearch:v2.5.2
- 镜像 Github 地址: https://github.com/my-dlq/fluentd-elasticsearch
创建 Fluentd
1$ kubectl apply -f fluentd.yaml
5、查看 Fluentd 相关资源
- -n:指定namespace,如果namespace是跟我不一致,请换到对应的 namespace
1$ kubectl get pod,daemonset -n logging | grep fluent
2
3pod/fluentd-es-cw6tj 1/1 Running 0 2m45s
4pod/fluentd-es-lt4cz 1/1 Running 0 2m45s
5pod/fluentd-es-x6hfg 1/1 Running 0 2m45s
6pod/fluentd-es-zpxql 1/1 Running 0 2m45s
7
8daemonset.extensions/fluentd-es 4 4 4 4 4 <none> 2m46s
六、Kibana 查看采集的日志信息
1、Kibana 设置索引
(1)、Kibana 中设置检索的索引
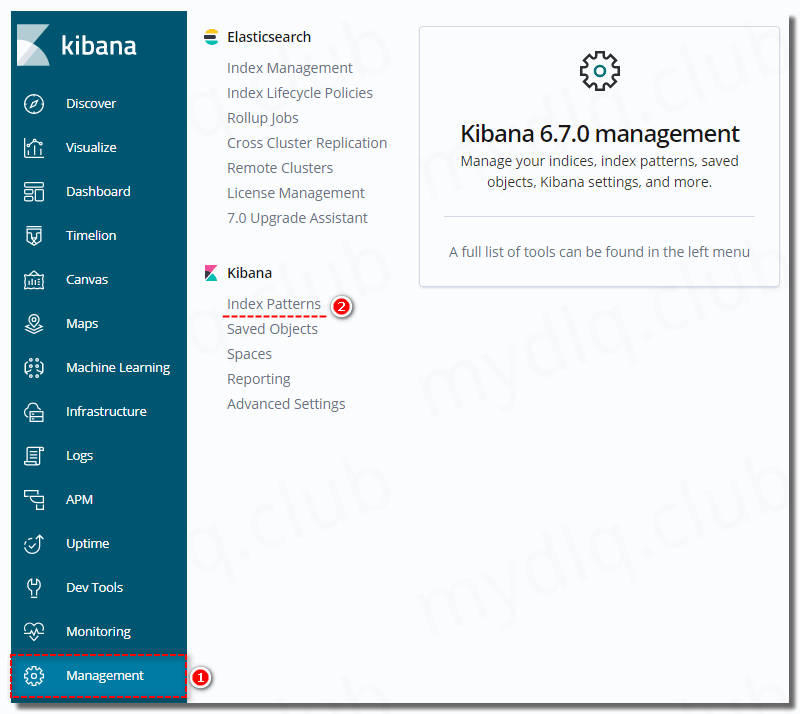
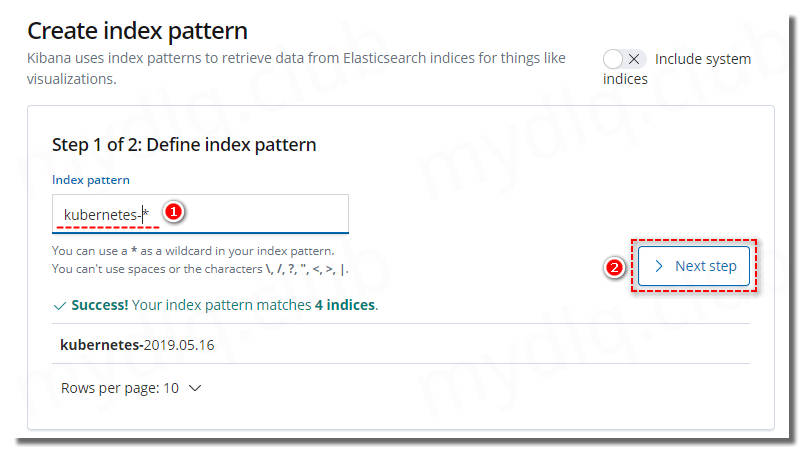
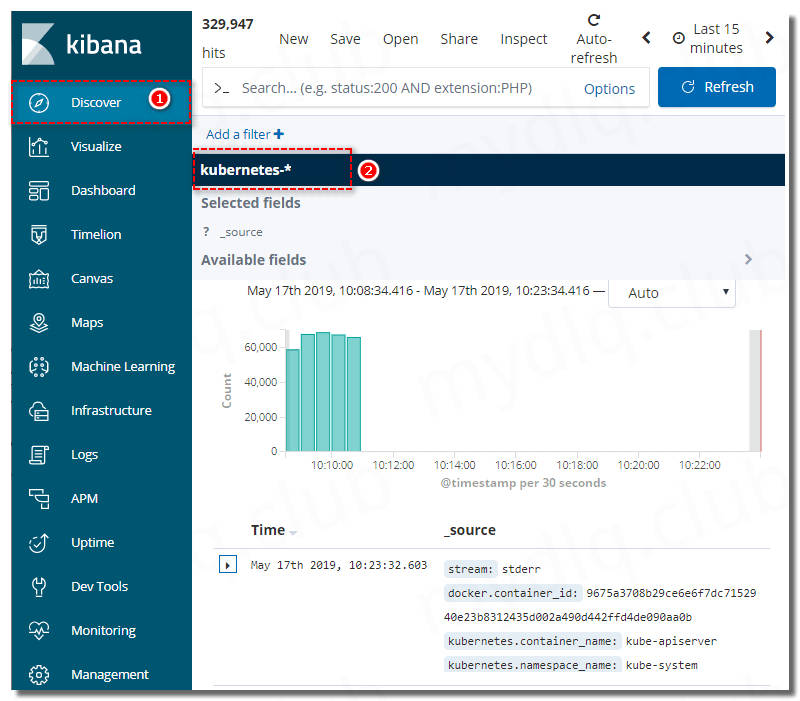
由于在 Fluentd 输出配置中配置了 “logstash_prefix kubernetes” 这个参数,所以索引是以 kubernetes 为前缀显示,如果未设置则默认为 “logstash” 为前缀。
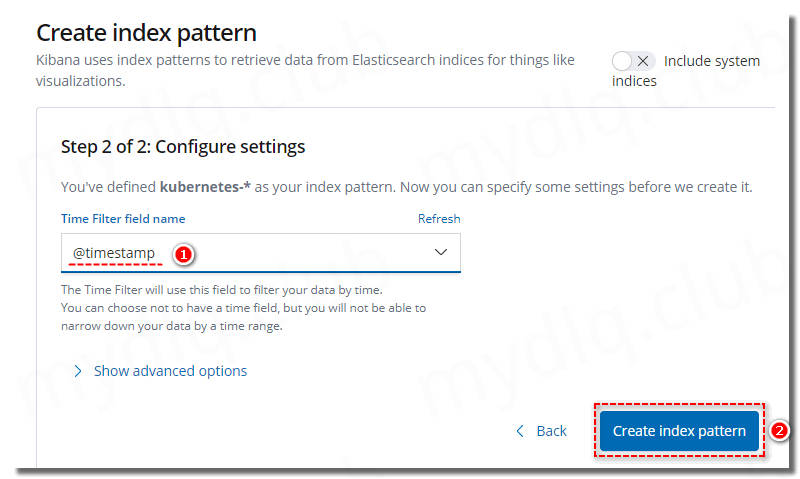
2、Kibana 查看 Kubernetes 日志信息


!版权声明:本博客内容均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。