
使用 Prometheus Operator 监控 Kubernetes 集群(Prometheus Operator 已改名为 Kube-Prometheus)
文章目录
!版权声明:本博客内容均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。
注意:
Prometheus-operator 已经改名为 Kube-promethues
参考:
- https://www.liangzl.com/get-article-detail-126792.html
- https://blog.51cto.com/zgui2000/2388379
- http://www.gdjmqj.com/news/hulianwang/10721.html
系统参数:
- Prometheus Operator版本: 0.29 (Prometheus Operator更名为Kube-Prometheus,且版本变为:0.1.0)
- Kubernetes 版本: 1.14.0
- 项目 Github 地址: https://github.com/coreos/kube-prometheus
更快捷部署
可以从本人的 Github 下载已经修改过的部署文件进行快速部署,不必按博文修改配置,按照里面的 README.md 部署说明进行安装即可,顺便点颗小星星哦。
地址: https://github.com/my-dlq/blog-example/tree/master/kubernetes/prometheus-operator
这里推荐手动下来源码安装,不推荐 helm 方式,因为很多东西需要手动配置进行改动。
一、介绍
1、Kubernetes Operator 介绍
在 Kubernetes 的支持下,管理和伸缩 Web 应用、移动应用后端以及 API 服务都变得比较简单了。其原因是这些应用一般都是无状态的,所以 Deployment 这样的基础 Kubernetes API 对象就可以在无需附加操作的情况下,对应用进行伸缩和故障恢复了。
而对于数据库、缓存或者监控系统等有状态应用的管理,就是个挑战了。这些系统需要应用领域的知识,来正确的进行伸缩和升级,当数据丢失或不可用的时候,要进行有效的重新配置。我们希望这些应用相关的运维技能可以编码到软件之中,从而借助 Kubernetes 的能力,正确的运行和管理复杂应用。
Operator 这种软件,使用 TPR(第三方资源,现在已经升级为 CRD) 机制对 Kubernetes API 进行扩展,将特定应用的知识融入其中,让用户可以创建、配置和管理应用。和 Kubernetes 的内置资源一样,Operator 操作的不是一个单实例应用,而是集群范围内的多实例。
2、Prometheus Operator 介绍
Kubernetes 的 Prometheus Operator 为 Kubernetes 服务和 Prometheus 实例的部署和管理提供了简单的监控定义。
安装完毕后,Prometheus Operator提供了以下功能:
- 创建/毁坏: 在 Kubernetes namespace 中更容易启动一个 Prometheus 实例,一个特定的应用程序或团队更容易使用Operator。
- 简单配置: 配置 Prometheus 的基础东西,比如在 Kubernetes 的本地资源 versions, persistence, retention policies, 和 replicas。
- Target Services 通过标签: 基于常见的Kubernetes label查询,自动生成监控target 配置;不需要学习普罗米修斯特定的配置语言。
3、Prometheus Operator 系统架构图

- Operator: Operator 资源会根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus: Prometheus 资源是声明性地描述 Prometheus 部署的期望状态。
- Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
- ServiceMonitor: ServiceMonitor 也是一个自定义资源,它描述了一组被 Prometheus 监控的 targets 列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
- Service: Service 资源主要用来对应 Kubernetes 集群中的 Metrics Server Pod,来提供给 ServiceMonitor 选取让 Prometheus Server 来获取信息。简单的说就是 Prometheus 监控的对象,例如 Node Exporter Service、Mysql Exporter Service 等等。
- Alertmanager: Alertmanager 也是一个自定义资源类型,由 Operator 根据资源描述内容来部署 Alertmanager 集群。
二、拉取 Prometheus Operator
先从 Github 上将源码拉取下来,利用源码项目已经写好的 kubernetes 的 yaml 文件进行一系列集成镜像的安装,如 grafana、prometheus 等等。
从 GitHub 拉取 Prometheus Operator 源码
1$ wget https://github.com/coreos/kube-prometheus/archive/v0.1.0.tar.gz
解压
1$ tar -zxvf v0.1.0.tar.gz
三、进行文件分类
由于它的文件都存放在项目源码的 manifests 文件夹下,所以需要进入其中进行启动这些 kubernetes 应用 yaml 文件。又由于这些文件堆放在一起,不利于分类启动,所以这里将它们分类。
进入源码的 manifests 文件夹
1$ cd kube-prometheus-0.1.0/manifests/
创建文件夹并且将 yaml 文件分类
1# 创建文件夹
2$ mkdir -p operator node-exporter alertmanager grafana kube-state-metrics prometheus serviceMonitor adapter
3
4# 移动 yaml 文件,进行分类到各个文件夹下
5mv *-serviceMonitor* serviceMonitor/
6mv 0prometheus-operator* operator/
7mv grafana-* grafana/
8mv kube-state-metrics-* kube-state-metrics/
9mv alertmanager-* alertmanager/
10mv node-exporter-* node-exporter/
11mv prometheus-adapter* adapter/
12mv prometheus-* prometheus/
基本目录结构如下:
1manifests/
2├── 00namespace-namespace.yaml
3├── adapter
4│ ├── prometheus-adapter-apiService.yaml
5│ ├── prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml
6│ ├── prometheus-adapter-clusterRoleBindingDelegator.yaml
7│ ├── prometheus-adapter-clusterRoleBinding.yaml
8│ ├── prometheus-adapter-clusterRoleServerResources.yaml
9│ ├── prometheus-adapter-clusterRole.yaml
10│ ├── prometheus-adapter-configMap.yaml
11│ ├── prometheus-adapter-deployment.yaml
12│ ├── prometheus-adapter-roleBindingAuthReader.yaml
13│ ├── prometheus-adapter-serviceAccount.yaml
14│ └── prometheus-adapter-service.yaml
15├── alertmanager
16│ ├── alertmanager-alertmanager.yaml
17│ ├── alertmanager-secret.yaml
18│ ├── alertmanager-serviceAccount.yaml
19│ └── alertmanager-service.yaml
20├── grafana
21│ ├── grafana-dashboardDatasources.yaml
22│ ├── grafana-dashboardDefinitions.yaml
23│ ├── grafana-dashboardSources.yaml
24│ ├── grafana-deployment.yaml
25│ ├── grafana-serviceAccount.yaml
26│ └── grafana-service.yaml
27├── kube-state-metrics
28│ ├── kube-state-metrics-clusterRoleBinding.yaml
29│ ├── kube-state-metrics-clusterRole.yaml
30│ ├── kube-state-metrics-deployment.yaml
31│ ├── kube-state-metrics-roleBinding.yaml
32│ ├── kube-state-metrics-role.yaml
33│ ├── kube-state-metrics-serviceAccount.yaml
34│ └── kube-state-metrics-service.yaml
35├── node-exporter
36│ ├── node-exporter-clusterRoleBinding.yaml
37│ ├── node-exporter-clusterRole.yaml
38│ ├── node-exporter-daemonset.yaml
39│ ├── node-exporter-serviceAccount.yaml
40│ └── node-exporter-service.yaml
41├── operator
42│ ├── 0prometheus-operator-0alertmanagerCustomResourceDefinition.yaml
43│ ├── 0prometheus-operator-0prometheusCustomResourceDefinition.yaml
44│ ├── 0prometheus-operator-0prometheusruleCustomResourceDefinition.yaml
45│ ├── 0prometheus-operator-0servicemonitorCustomResourceDefinition.yaml
46│ ├── 0prometheus-operator-clusterRoleBinding.yaml
47│ ├── 0prometheus-operator-clusterRole.yaml
48│ ├── 0prometheus-operator-deployment.yaml
49│ ├── 0prometheus-operator-serviceAccount.yaml
50│ └── 0prometheus-operator-service.yaml
51├── prometheus
52│ ├── prometheus-clusterRoleBinding.yaml
53│ ├── prometheus-clusterRole.yaml
54│ ├── prometheus-prometheus.yaml
55│ ├── prometheus-roleBindingConfig.yaml
56│ ├── prometheus-roleBindingSpecificNamespaces.yaml
57│ ├── prometheus-roleConfig.yaml
58│ ├── prometheus-roleSpecificNamespaces.yaml
59│ ├── prometheus-rules.yaml
60│ ├── prometheus-serviceAccount.yaml
61│ └── prometheus-service.yaml
62└── serviceMonitor
63 ├── 0prometheus-operator-serviceMonitor.yaml
64 ├── alertmanager-serviceMonitor.yaml
65 ├── grafana-serviceMonitor.yaml
66 ├── kube-state-metrics-serviceMonitor.yaml
67 ├── node-exporter-serviceMonitor.yaml
68 ├── prometheus-serviceMonitorApiserver.yaml
69 ├── prometheus-serviceMonitorCoreDNS.yaml
70 ├── prometheus-serviceMonitorKubeControllerManager.yaml
71 ├── prometheus-serviceMonitorKubelet.yaml
72 ├── prometheus-serviceMonitorKubeScheduler.yaml
73 └── prometheus-serviceMonitor.yaml
四、修改源码 yaml 文件
由于这些 yaml 文件中设置的应用镜像国内无法拉取下来,所以修改源码中的这些 yaml 的镜像设置,替换镜像地址方便拉取安装。再之后因为需要将 Grafana & Prometheus 通过 NodePort 方式暴露出去,所以也需要修改这两个应用的 service 文件。
可以从本人的 Github 下载已经修改过的部署文件,地址: https://github.com/my-dlq/blog-example/tree/master/prometheus-operator 可以按照里面的 README.md 部署说明进行安装部署。
1、修改镜像
(1)、修改 operator
修改 0prometheus-operator-deployment.yaml
1$ vim operator/0prometheus-operator-deployment.yaml
改成如下:
1......
2 containers:
3 - args:
4 - --kubelet-service=kube-system/kubelet
5 - --logtostderr=true
6 - --config-reloader-image=quay.io/coreos/configmap-reload:v0.0.1 #修改镜像
7 - --prometheus-config-reloader=quay.io/coreos/prometheus-config-reloader:v0.29.0 #修改镜像
8 image: quay.io/coreos/prometheus-operator:v0.29.0 #修改镜像
9......
(2)、修改 adapter
修改 prometheus-adapter-deployment.yaml
1$ vim adapter/prometheus-adapter-deployment.yaml
改成如下:
1......
2 containers:
3 - args:
4 - --cert-dir=/var/run/serving-cert
5 - --config=/etc/adapter/config.yaml
6 - --logtostderr=true
7 - --metrics-relist-interval=1m
8 - --prometheus-url=http://prometheus-k8s.monitoring.svc:9090/
9 - --secure-port=6443
10 image: quay.io/coreos/k8s-prometheus-adapter-amd64:v0.4.1 #修改镜像
11 name: prometheus-adapter
12......
(3)、修改 alertmanager
修改 alertmanager-alertmanager.yaml
1$ vim alertmanager/alertmanager-alertmanager.yaml
改成如下:
1......
2spec:
3 baseImage: quay.io/prometheus/alertmanager #修改镜像
4 nodeSelector:
5 beta.kubernetes.io/os: linux
6 replicas: 3
7 securityContext:
8 fsGroup: 2000
9 runAsNonRoot: true
10 runAsUser: 1000
11 serviceAccountName: alertmanager-main
12 version: v0.17.0
(4)、修改 node-exporter
修改 node-exporter-daemonset.yaml
1$ vim node-exporter/node-exporter-daemonset.yaml
改成如下:
1......
2 containers:
3 - args:
4 - --web.listen-address=127.0.0.1:9100
5 image: quay.io/prometheus/node-exporter:v0.17.0 #修改镜像
6
7 ......
8
9 - args:
10 - --logtostderr
11 - --upstream=http://127.0.0.1:9100/
12 image: quay.io/coreos/kube-rbac-proxy:v0.4.1 #修改镜像
13......
(5)、修改 kube-state-metrics
修改 kube-state-metrics-deployment.yaml 文件
1$ vim kube-state-metrics/kube-state-metrics-deployment.yaml
改成如下:
1......
2 containers:
3 - args:
4 - --logtostderr
5 - --secure-listen-address=:8443
6 - --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
7 - --upstream=http://127.0.0.1:8081/
8 image: quay.io/coreos/kube-rbac-proxy:v0.4.1 #修改镜像
9 name: kube-rbac-proxy-main
10 - args:
11 - --logtostderr
12 - --secure-listen-address=:9443
13 - --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
14 - --upstream=http://127.0.0.1:8082/
15 image: quay.io/coreos/kube-rbac-proxy:v0.4.1 #修改镜像
16 name: kube-rbac-proxy-self
17 - args:
18 - --host=127.0.0.1
19 - --port=8081
20 - --telemetry-host=127.0.0.1
21 - --telemetry-port=8082
22 image: quay.io/coreos/kube-state-metrics:v1.5.0 #修改镜像
23 name: kube-state-metrics
24 - command:
25 - /pod_nanny
26 - --container=kube-state-metrics
27 - --deployment=kube-state-metrics
28 - name: MY_POD_NAMESPACE
29 valueFrom:
30 fieldRef:
31 apiVersion: v1
32 fieldPath: metadata.namespace
33 image: registry.aliyuncs.com/google_containers/addon-resizer:1.8.4 #修改镜像
34 name: addon-resizer
35......
(6)、修改 node-exporter
修改 node-exporter-daemonset.yaml 文件
1$ vim prometheus/prometheus-prometheus.yaml
改成如下:
1......
2spec:
3 alerting:
4 alertmanagers:
5 - name: alertmanager-main
6 namespace: monitoring
7 port: web
8 baseImage: quay.io/prometheus/prometheus #修改镜像
9 nodeSelector:
10 beta.kubernetes.io/os: linux
11 replicas: 2
12 resources:
13 requests:
14 memory: 400Mi
15 ruleSelector:
16 matchLabels:
17 prometheus: k8s
18 role: alert-rules
19 securityContext:
20 fsGroup: 2000
21 runAsNonRoot: true
22 runAsUser: 1000
23 serviceAccountName: prometheus-k8s
24 serviceMonitorNamespaceSelector: {}
25 serviceMonitorSelector: {}
26 version: v2.7.2
2、修改 Service 端口设置
(1)、修改 Prometheus Service
修改 prometheus-service.yaml 文件
1$ vim prometheus/prometheus-service.yaml
修改prometheus Service端口类型为NodePort,设置nodePort端口为32101
1apiVersion: v1
2kind: Service
3metadata:
4 labels:
5 prometheus: k8s
6 name: prometheus-k8s
7 namespace: monitoring
8spec:
9 type: NodePort
10 ports:
11 - name: web
12 port: 9090
13 targetPort: web
14 nodePort: 32101
15 selector:
16 app: prometheus
17 prometheus: k8s
18 sessionAffinity: ClientIP
(2)、修改 Grafana Service
修改 grafana-service.yaml 文件
1$ vim grafana/grafana-service.yaml
修改garafana Service端口类型为NodePort,设置nodePort端口为32102
1apiVersion: v1
2kind: Service
3metadata:
4 labels:
5 app: grafana
6 name: grafana
7 namespace: monitoring
8spec:
9 type: NodePort
10 ports:
11 - name: http
12 port: 3000
13 targetPort: http
14 nodePort: 32102
15 selector:
16 app: grafana
3、修改数据持久化存储
prometheus 实际上是通过 emptyDir 进行挂载的,我们知道 emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,如果 Pod 挂掉了,那么数据也就丢失了,这也就是为什么我们重建 Pod 后之前的数据就没有了的原因,所以这里修改它的持久化配置。
(1)、创建 StorageClass
创建一个名称为 fast 的 StorageClass,不同的存储驱动创建的 StorageClass 配置也不同,下面提供基于"GlusterFS"和"NFS"两种配置,如果是NFS存储,请提前确认集群中是否存在"nfs-provisioner"应用。
GlusterFS 存储的 StorageClass 配置
1apiVersion: storage.k8s.io/v1
2kind: StorageClass
3metadata:
4 name: fast #---SorageClass 名称
5provisioner: kubernetes.io/glusterfs #---标识 provisioner 为 GlusterFS
6parameters:
7 resturl: "http://10.10.249.63:8080"
8 restuser: "admin"
9 gidMin: "40000"
10 gidMax: "50000"
11 volumetype: "none" #---分布巻模式,不提供备份,正式环境切勿用此模式
NFS 存储的 StorageClass 配置
1apiVersion: storage.k8s.io/v1
2kind: StorageClass
3metadata:
4 name: fast
5provisioner: nfs-client #---动态卷分配应用设置的名称,必须和集群中的"nfs-provisioner"应用设置的变量名称保持一致
6parameters:
7 archiveOnDelete: "true" #---设置为"false"时删除PVC不会保留数据,"true"则保留数据
(2)、修改 Prometheus 持久化
修改 prometheus-prometheus.yaml 文件
1$ vim prometheus/prometheus-prometheus.yaml
prometheus是一种 StatefulSet 有状态集的部署模式,所以直接将 StorageClass 配置到里面,在下面的yaml中最下面添加持久化配置:
1apiVersion: monitoring.coreos.com/v1
2kind: Prometheus
3metadata:
4 labels:
5 prometheus: k8s
6 name: k8s
7 namespace: monitoring
8spec:
9 alerting:
10 alertmanagers:
11 - name: alertmanager-main
12 namespace: monitoring
13 port: web
14 baseImage: quay.io/prometheus/prometheus
15 nodeSelector:
16 beta.kubernetes.io/os: linux
17 replicas: 2
18 resources:
19 requests:
20 memory: 400Mi
21 ruleSelector:
22 matchLabels:
23 prometheus: k8s
24 role: alert-rules
25 securityContext:
26 fsGroup: 2000
27 runAsNonRoot: true
28 runAsUser: 1000
29 serviceAccountName: prometheus-k8s
30 serviceMonitorNamespaceSelector: {}
31 serviceMonitorSelector: {}
32 version: v2.7.2
33 storage: #----添加持久化配置,指定StorageClass为上面创建的fast
34 volumeClaimTemplate:
35 spec:
36 storageClassName: fass #---指定为fast
37 resources:
38 requests:
39 storage: 10Gi
(3)、修改 Grafana 持久化配置
创建 grafana-pvc.yaml 文件
由于 Grafana 是部署模式为 Deployment,所以我们提前为其创建一个 grafana-pvc.yaml 文件,加入下面 PVC 配置。
1kind: PersistentVolumeClaim
2apiVersion: v1
3metadata:
4 name: grafana
5 namespace: monitoring #---指定namespace为monitoring
6spec:
7 storageClassName: fast #---指定StorageClass为上面创建的fast
8 accessModes:
9 - ReadWriteOnce
10 resources:
11 requests:
12 storage: 5Gi
修改 grafana-deployment.yaml 文件设置持久化配置,应用上面的 PVC
1$ vim grafana/grafana-deployment.yaml
将 volumes 里面的 “grafana-storage” 配置注掉,新增如下配置,挂载一个名为 grafana 的 PVC
1......
2 volumes:
3 - name: grafana-storage #-------新增持久化配置
4 persistentVolumeClaim:
5 claimName: grafana #-------设置为创建的PVC名称
6 #- emptyDir: {} #-------注释掉旧的配置
7 # name: grafana-storage
8 - name: grafana-datasources
9 secret:
10 secretName: grafana-datasources
11 - configMap:
12 name: grafana-dashboards
13 name: grafana-dashboards
14......
五、部署前各节点提前下载镜像
为了保证服务启动速度,所以最好部署节点提前下载所需镜像。
1docker pull quay.io/coreos/configmap-reload:v0.0.1
2docker pull quay.io/coreos/prometheus-config-reloader:v0.29.0
3docker pull quay.io/coreos/prometheus-operator:v0.29.0
4docker pull quay.io/coreos/k8s-prometheus-adapter-amd64:v0.4.1
5docker pull quay.io/prometheus/alertmanager:v0.17.0
6docker pull quay.io/prometheus/node-exporter:v0.17.0
7docker pull quay.io/coreos/kube-rbac-proxy:v0.4.1
8docker pull quay.io/coreos/kube-state-metrics:v1.5.0
9docker pull registry.aliyuncs.com/google_containers/addon-resizer:1.8.4
10docker pull quay.io/prometheus/prometheus:v2.7.2
六、更改 kubernetes 配置与创建对应 Service
必须提前设置一些 Kubernetes 中的配置,否则 kube-scheduler 和 kube-controller-manager 无法监控到数据。
1、更改 kubernetes 配置
由于 Kubernetes 集群是由 kubeadm 搭建的,其中 kube-scheduler 和 kube-controller-manager 默认绑定 IP 是 127.0.0.1 地址。Prometheus Operator 是通过节点 IP 去访问,所以我们将 kube-scheduler 绑定的地址更改成 0.0.0.0。
(1)、修改 kube-scheduler 配置
编辑 /etc/kubernetes/manifests/kube-scheduler.yaml 文件
1$ vim /etc/kubernetes/manifests/kube-scheduler.yaml
将 command 的 bind-address 地址更改成 0.0.0.0
1......
2spec:
3 containers:
4 - command:
5 - kube-scheduler
6 - --bind-address=0.0.0.0 #改为0.0.0.0
7 - --kubeconfig=/etc/kubernetes/scheduler.conf
8 - --leader-elect=true
9......
(2)、修改 kube-controller-manager 配置
编辑 /etc/kubernetes/manifests/kube-controller-manager.yaml 文件
1$ vim /etc/kubernetes/manifests/kube-controller-manager.yaml
将 command 的 bind-address 地址更改成 0.0.0.0
1spec:
2 containers:
3 - command:
4 - kube-controller-manager
5 - --allocate-node-cidrs=true
6 - --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
7 - --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
8 - --bind-address=0.0.0.0 #改为0.0.0.0
9......
2、创建 kube-scheduler & controller-manager 对应 Service
因为 Prometheus Operator 配置监控对象 serviceMonitor 是根据 label 选取 Service 来进行监控关联的,而通过 Kuberadm 安装的 Kubernetes 集群只创建了 kube-scheduler & controller-manager 的 Pod 并没有创建 Service,所以 Prometheus Operator 无法这两个组件信息,这里我们收到创建一下这俩个组件的 Service。
1apiVersion: v1
2kind: Service
3metadata:
4 namespace: kube-system
5 name: kube-controller-manager
6 labels:
7 k8s-app: kube-controller-manager
8spec:
9 selector:
10 component: kube-controller-manager
11 type: ClusterIP
12 clusterIP: None
13 ports:
14 - name: http-metrics
15 port: 10252
16 targetPort: 10252
17 protocol: TCP
18---
19apiVersion: v1
20kind: Service
21metadata:
22 namespace: kube-system
23 name: kube-scheduler
24 labels:
25 k8s-app: kube-scheduler
26spec:
27 selector:
28 component: kube-scheduler
29 type: ClusterIP
30 clusterIP: None
31 ports:
32 - name: http-metrics
33 port: 10251
34 targetPort: 10251
35 protocol: TCP
如果是二进制部署还得创建对应的 Endpoints 对象将两个组件挂入到 kubernetes 集群内,然后通过 Service 提供访问,才能让 Prometheus 监控到。
七、安装Prometheus Operator
所有文件都在 manifests 目录下执行。
1、创建 namespace
1$ kubectl apply -f 00namespace-namespace.yaml
2、安装 Operator
1$ kubectl apply -f operator/
查看 Pod,等 pod 创建起来在进行下一步
1$ kubectl get pods -n monitoring
2
3NAME READY STATUS RESTARTS
4prometheus-operator-5d6f6f5d68-mb88p 1/1 Running 0
3、安装其它组件
1kubectl apply -f adapter/
2kubectl apply -f alertmanager/
3kubectl apply -f node-exporter/
4kubectl apply -f kube-state-metrics/
5kubectl apply -f grafana/
6kubectl apply -f prometheus/
7kubectl apply -f serviceMonitor/
查看 Pod 状态
1$ kubectl get pods -n monitoring
2
3NAME READY STATUS RESTARTS
4alertmanager-main-0 2/2 Running 0
5alertmanager-main-1 2/2 Running 0
6alertmanager-main-2 2/2 Running 0
7grafana-b6bd6d987-2kr8w 1/1 Running 0
8kube-state-metrics-6f7cd8cf48-ftkjw 4/4 Running 0
9node-exporter-4jt26 2/2 Running 0
10node-exporter-h88mw 2/2 Running 0
11node-exporter-mf7rr 2/2 Running 0
12prometheus-adapter-df8b6c6f-jfd8m 1/1 Running 0
13prometheus-k8s-0 3/3 Running 0
14prometheus-k8s-1 3/3 Running 0
15prometheus-operator-5d6f6f5d68-mb88p 1/1 Running 0
八、查看 Prometheus & Grafana
1、查看 Prometheus
打开地址: http://192.168.2.11:32101 查看 Prometheus 采集的目标,看其各个采集服务状态有木有错误。

2、查看 Grafana
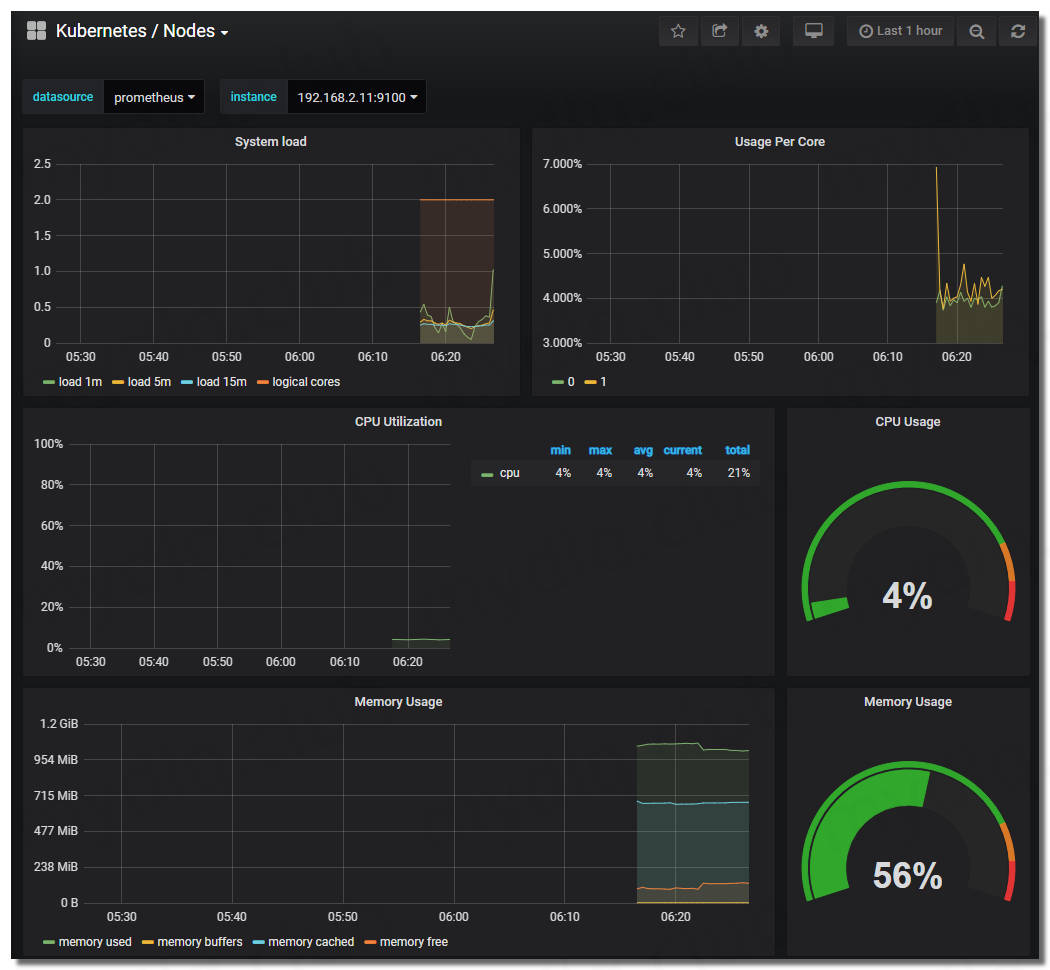
打开地址: http://192.168.2.11:32102 查看 Grafana 图表,看其 Kubernetes 集群是否能正常显示。
- 默认用户名:admin
- 默认密码:admin

可以看到各种仪表盘

!版权声明:本博客内容均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。